
チューリング賞受賞者のヤン・ルカンが、新会社を立ち上げた。チューリング賞は「コンピュータ科学のノーベル賞」と呼ばれる最高の栄誉。
名前はAMI Labs(Advanced Machine Intelligence Labs)。最初の資金調達(シードラウンド)で集めた額は約1,500億円(10.3億ドル)。創業直後の資金調達としてはヨーロッパ史上最大。

ルカンといえば、ディープラーニングの父と呼ばれる人物。MetaのチーフAIサイエンティストを長年務めていたが、2025年11月に退任。そして2026年3月、自分の会社を正式に立ち上げた。

ルカンが言い続けてきたこと
ルカンがここ数年、一貫して主張してきたことがある。
「LLMをスケールさせても、AGIには到達しない」
NVIDIAのGTCカンファレンスでも、はっきりこう言っている。
さらに踏み込んで、「LLMで超知能に到達するという考えは、完全にナンセンスだ」とまで言い切っている。
若い研究者へのアドバイスとしても「LLMに取り組むな。次世代のAIシステムに取り組め」と。
LLMではAGIに到達できないという主張
ルカンが指摘するLLMの根本的な限界は4つある。
1. 世界を理解していない
LLMはテキストの統計的パターンを学習しているだけで、物理世界を理解していない。「重力」という言葉が他の単語とどう関連するかは知っているが、重力そのものは理解していない。
ルカン自身の言葉を借りれば、「カップがテーブルを通り抜けない理由すら、LLMは本当には理解していない」。
4歳の子どもは約10の15乗バイトの視覚・感覚データを処理して世界を学ぶ。LLMが学習するテキストデータは10の13乗バイト。言語は現実のごく一部を切り取った、極めて低帯域の表現に過ぎない。
2. 計画が立てられない
LLMは「次の1トークン」を予測することしかできない。1トークンあたりの計算量は固定で、先を見通して計画を立てるという概念がない。
ルカンはこう言っている。「自己回帰型LLMは計画を立てられない。本当の意味で推論もできない。基本的に、これから何を言うか事前に考えることなく、ただ一語ずつ生成しているだけだ」
計画を立てるには、世界モデルで結果をシミュレーションし、コスト関数で評価し、最適化する仕組みが必要。LLMにはそのどれもない。
3. 深い推論ができない
心理学でいう「システム1」(直感的・反射的な判断)はできるが、「システム2」(ゆっくり考える深い推論)ができない。1トークンあたりの計算量が固定なので、難しい問題に「もっと考える」ということができない。
4. ハルシネーションは構造的に直せない
LLMのハルシネーション(嘘をつく問題)は、学習データやファインチューニングの問題ではなく、アーキテクチャの構造的な問題。数学的な研究でも「LLMはすべての計算可能な関数を学習できないため、汎用的な問題解決に使えば必ずハルシネーションが発生する」ことが示されている。
ルカンの結論は明確。「今のLLMと同じ設計図で作られたAIは、どれだけ知識が豊富になっても、依然として愚かで、ハルシネーションし続け、制御が困難なままだ」
世界モデルという「別の道」
ルカンが提唱するのは、LLMとは根本的に異なるアプローチ。
LLMは「次の単語」を予測する。画像生成AIは「次のピクセル」を予測する。
世界モデル(JEPA)は「次の状態の抽象的な表現」を予測する。
この違いが決定的に重要。
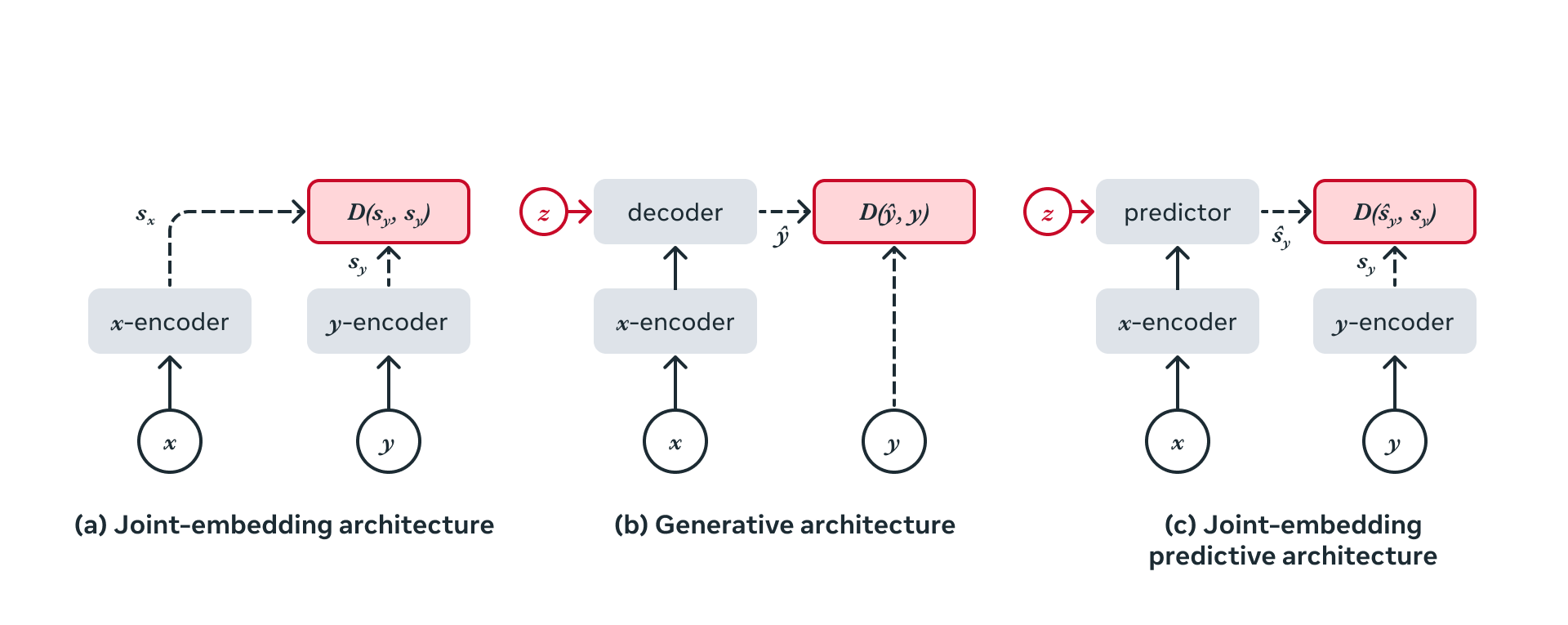
現実世界は部分的にしか予測できない。ボールを投げたとき、だいたいどこに落ちるかは予測できるが、空気の分子の動きまでは予測できない。
生成モデル(LLMや画像生成AI)はすべての細部を予測しようとするから、ノイズや無関係な情報にも計算資源を浪費する。
JEPAは予測不可能な細部を無視し、意味のある抽象的な構造だけを学習する。人間が「次に何が起きるか」を考えるとき、ピクセル単位の画像を脳内で生成するわけではない。物体の性質や相互作用を抽象的に考える。JEPAはそれと同じことをやろうとしている。
そしてここが最も重要な点。JEPAには2つの動作モードがある。
- モード1(反射的): LLMと同様の高速な判断。学習済みのパターンから即座に反応する
- モード2(熟考的): 世界モデルの中で複数の行動シーケンスをシミュレーションし、コストを評価し、最適な行動を選択する。これが本物の「計画」であり「推論」
LLMには「モード2」が根本的にない。JEPAにはある。これが世界モデルが注目される最大の理由。もちろん、このアプローチが本当にAGIに繋がるかはまだ誰にもわからない。ただ、LLMとはまったく異なる角度からの挑戦であることは間違いない。
世界モデルはどうやって作るのか
AMI Labsの具体的なアプローチも見えてきている。
Metaの研究チーム時代にルカンが手がけたJEPAの進化は段階的だった。
- I-JEPA(2023年): 画像から学習。画像の一部をマスクして、残りから予測する
- V-JEPA(2024年): 動画に拡張。時間軸を含む3次元データとして学習
- V-JEPA 2(2025年): 2,200万本の動画(100万時間以上)で学習。ロボット制御にも対応
V-JEPA 2では驚くべき成果が出ている。たった62時間のラベルなしロボット映像で学習しただけで、ゼロショットのロボット制御(物体のピック&プレース)を2つの異なる研究室で実現した。タスク専用の学習も、報酬関数の設計も不要。
これは「テキストだけでは学べないことが、動画と物理世界のデータから学べる」というルカンの主張を裏付けている。
ルカンが2022年の論文で提案した認知アーキテクチャは6つのモジュールで構成される。
- 知覚モジュール: センサーから世界の状態を推定
- 世界モデル(中核): 不足情報を補完し、未来の状態を予測する「現実のシミュレーター」
- コストモジュール: 結果を評価する
- アクターモジュール: 行動を提案する
- 短期記憶: 世界の状態とコストを蓄積
- コンフィギュレーター: 全モジュールを調整する「オーケストラの指揮者」
この設計思想は、人間の脳がどのように世界を理解し、計画を立て、行動するかをモデル化している。テキスト予測の延長線上にはない、まったく異なるアプローチ。
世界モデルの課題
もちろん、世界モデルにも大きな課題がある。
学習データの壁
LLMはインターネット上の膨大なテキストで学習できる。データは事実上無限にある。一方、世界モデルが必要とするのは高品質な動画やセンサーデータ。テキストと比べて収集・整理のコストが桁違いに高い。V-JEPA 2は2,200万本の動画で学習したが、物理世界の複雑さを網羅するにはまだ全然足りない。
評価が難しい
LLMなら「この質問に正しく答えられるか」でベンチマークできる。世界モデルは「世界をどれだけ正しく理解しているか」を測る必要があるが、そのための標準的なベンチマークがまだ確立されていない。成果を証明しにくい。
商用化までの距離
LLMはChatGPTという形で即座にビジネスになった。世界モデルはロボティクスや産業制御が主な応用先で、実世界での検証に時間がかかる。AMI Labs自身が「最初の1年は純粋な研究」と言っているように、収益化は数年先。1,500億円の資金がいつまで持つかという現実もある。
LLMの急速な進化
ルカンが「LLMでは不可能」と主張している計画や推論の能力を、LLM側も改善し続けている。Chain-of-Thoughtやツール利用、マルチモーダル対応など。世界モデルが完成する前にLLMが「十分に使える」レベルに達してしまう可能性もある。
これらの課題があるからこそ、世界モデルは「確実な勝者」ではなく「注目すべき挑戦者」。ただ、課題があること自体は否定材料にならない。LLMだって初期には「使い物にならない」と言われていた。
誰が出資しているのか
投資家の顔ぶれが、この会社の本気度を物語っている。
- NVIDIA
- ジェフ・ベゾス(Bezos Expeditions)
- エリック・シュミット(元Google CEO)
- マーク・キューバン
- Samsung、Toyota Ventures、Temasek(シンガポール政府系ファンド)
プレマネーの評価額は約5,250億円(35億ドル)。シードラウンドでこの規模は異常。
NVIDIAが出資しているのが特に意味深い。ハードウェア側も「LLMの次」に賭け始めている、ということ。
面白いのは、AMI Labsの本社がパリにあること。ニューヨーク、モントリオール、シンガポール、チューリッヒにもオフィスを構えるが、メインはパリ。
AI開発の中心地といえばサンフランシスコだが、ルカンはあえてそこを避けた。ヨーロッパ発のAI企業として、独自のポジションを築こうとしている。
これは「LLMが終わる」という話ではない
誤解しないでほしいのは、今のLLMが使えないという話ではないということ。
ChatGPTもClaudeもGeminiも、ビジネスの現場で十分に役立っている。テキストベースのタスクにおいて、LLMは今も最強のツール。
ただ、ルカンが見ているのはもっと先。
ロボティクス、自動運転、医療、産業制御。こうした「物理世界で判断を下すAI」には、テキスト予測とは根本的に違うアプローチが必要だというのがルカンの主張。
ルカン自身、「現在のLLMは5年以内に概ね時代遅れになる」と予測している。
正直、世界モデルが実用化されるのはまだ先の話。AMI Labs自身も「最初の1年は純粋な研究フェーズ」と明言している。
そして、世界モデルが本当にAGIに繋がるかどうかは、まだ誰にもわからない。LLMがこのまま進化して到達する可能性だってゼロではない。
ただ、確実に言えることがある。
LLM一強だったAIの世界に、まったく異なるアプローチで挑む勢力が現れた。しかもチューリング賞受賞者が率い、NVIDIA、ベゾス、シュミットが賭けている。
AI活用を考えるうえで、「AIの進化がどこに向かっているのか」を知っておくことは判断に直結する。LLMだけを見ていると、見えない景色がある。
AIの地図は、書き換わりつつある。
AI LIFEコミュニティでは、こうしたAI業界の最新動向や実践的な活用法について日々共有しています。
詳しくはこちら: AI LIFEコミュニティに参加する


